Tech stack for Search system with Micro-services architecture

Note: Initially I started to write this post as dairy of experiments, of and as how we can implement search system. Later on I published it to use for others. So there might be some Slang words. I will update them once I can. Till then, Thanks for reading.
I wanted to explore how I can implement full fledged search system with Micro-service architecture. This intriguing system led me to go through various links and Search Engine Software documentations. Peeking into the tech stack behind search system lead to a confusion to me when combined my Micro-service architecture. So I thought of writing a short summery of how we can implement.
There is 2 ways we can integrate Search System in our architecture. Here it goes:
1. Have a search layer abstracted in every repository
2. A separate search system
1. Have a search layer abstracted in every repository:
Pros:
- No need to maintain separate service for search
- Data doesn’t needs to be duplicated to different database
- Single point of error handling for a repository for search
- Instantly reflects the information changes in search results
Cons:
- Creating dedicated indexes (which will be used in search) in each database will create overhead
- This is most probably most weighted downside of this approach: For each service, context is different. Search system is based on these context merged. (like for user service, context contains user’s id, names, but when we are asking for a project, we need project info from project service, project’s creator info from user service, and project’s order status from order service). We need to call each service and merge results each time.
- Most of the filtering work is done on client side (we are calling multiple micro-services and merging results), so waste of cpu cycles on each call
- On each character typed from user, we need to make a call to each of the micro-service for the related result set
- Search result relevance will be of another level issue (max_score, result_count, sequence of result set)
2. A separate search system
Pros:
- Centralise search system is easy to maintain and all time high service availability can be assured to some level
- Queries and database calls are fast
- It rescues the coupling to other services. So less load on our main services (user service, store service etc), with which users will be directly interacting
- Adding feature to the service and blocking some of the modules is easy
- Monitoring, matrix generation, log analytics is easy
- With separate search system, we can have all the feature like spell check, locale, search with languages other than English
2. A separate search system
Cons:
- As it mentions, we need to create a separate service and database for this system
- Micro-service system is distributed, and data insertion is event based. Feeding the changes of data to search database will always have some milliseconds leg (if optimised properly)
- Data duplication will require. Which comes with extra cost on infrastructure
- With this approach, we will need to introduce a separate infrastructure to feed the data to the database (Queues, Message brokers, Storage)
Now main question: How to implement search?
1st approach architecture:
Going with 1st approach is kind of making and managing search system on our own which includes working with micro-services and searching through it. (Go through the cons section of 1st approach)
2nd approach architecture would look like this:

For second approach:
There are multiple open source Search Engine Software available which are mature enough.
1. Elastic Search
2. Algolia
3. Apache Solr
4. Sphinx
5. DataparkSearch Engine
6. Xapian
7. Our own search engine (I wouldn’t recommend this way)
We have some good comparison between them. Over here:
- https://medium.com/@matayoshi.mariano/elasticsearch-vs-algolia-96364f5567a3
- https://blog.algolia.com/algolia-v-elasticsearch-latency/
- https://stackshare.io/stackups/algolia-vs-elasticsearch
- https://logz.io/blog/solr-vs-elasticsearch/
With the search engine system, we need some ways to feed the data to the search database. Each Search Engine Software provides different ways to insert data into database (REST, importing from db, importing from csv etc…). But with use case, our system will need a some kind of queueing mechanism which inserts data to search engine database.
Below are some message-broker software:
1. Rabbitmq
2. SQS
3. Kafka
4. Redis
which is a quite common topic among the search developer community. The data which we need to pass decides which is better. I have found some of links comparing them are below:
- https://stackshare.io/stackups/amazon-sqs-vs-kafka-vs-rabbitmq
- https://stackoverflow.com/questions/29539443/redis-vs-rabbitmq-as-a-data-broker-messaging-system-in-between-logstash-and-elas/31530763
- https://stackoverflow.com/questions/28687295/sqs-vs-rabbitmq
How it will work in action:
For firing a search request, it will be like,
front-end will directly ask data from Search service and get back result through the Elastic client.
as shown here:

For entering data in Elastic search database we have two options.
1. Each micro-services directly calls RabbitMQ service
2. Micro-services call search service which will call RabbitMQ
1. Each micro-services directly calls RabbitMQ service
Diagram:

1. Each micro-services directly calls RabbitMQ service
Pros:
- Less overhead on our centralized search system.
- If search service is legging or not responding, our data will not be lost.
Cons:
- With distributed applications trying to enter data in elastic search (via RabbitMQ) we will need to introduce data processing (Log Stash).
Diagram:
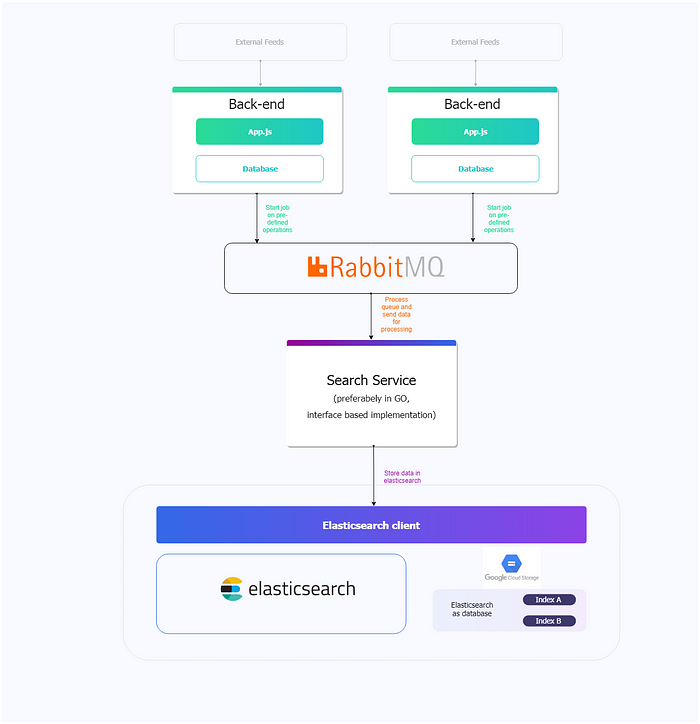
1. Each micro-services directly calls RabbitMQ service
Pros:
- Which data can be inserted in the elastic search database will be handled directly by our search system. That means power to have granular access to data.
- Changes to a single place will reflect results to our entire micro-services searches
- No need to maintain Log Stash or other data processing s/w
Cons:
- If centralize search system is down, data will be lost for ever and search won’t reflect newly created data anytime soon.
- Processing the data by our search system will have some adverse effect on performance on search.
